Natural Language Processing
Here is a small post on what comes after the natural language processing pipeline (e.g. from using spacy or nltk for example). For example, linking the words to their actual meaning using a sense database (such as WordNet) or extracting basic knowledge from the sentence structure.
While this may seem useless in 2024, one full year after ChatGPT came out, I still think it's an interesting topic worth exploring.

Prerequisites/Basics of NLP
The point of natural language processing is to either extract information from text or generate text from information.
Text for a computer is simply a chain of characters. In order to extract meaning of this text, we have to process it. There are 2 possibilities in python:
- NLTK - it mostly uses basic algorithms/regex to obtain results
- Spacy - it mostly uses statistical methods such as artificial neural networks
The pipeline for NLTK will look something like this:
import nltk
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords
text = "Hey! I'm going home."
# 1. tokenize the sentences ==> ['Hey!', "I'm going home."]
sentences = nltk.sent_tokenize(text)
# 2. tokenize the words ==> [['Hey', '!'], ['I', "'m", 'going', 'home', '.']]
sentences = [nltk.word_tokenize(sentence) for sentence in sentences]
# 3. remove stopwords (e.g. 'the' and the punctuation) & punctuation ==> [['Hey'], ['I', 'going', 'home']]
stopwords = set(stopwords.words('english'))
for i, sentence in enumerate(sentences):
sentences[i] = [word for word in sentence if word not in stopwords and word.isalnum()]
# 4. lemmatize the words ==> [['Hey'], ['I', 'going', 'home']]
lemmatizer = WordNetLemmatizer()
for i, sentence in enumerate(sentences):
sentences[i] = [lemmatizer.lemmatize(word) for word in sentence]
# 5. part of speech tagging
for i, sentence in enumerate(sentences):
sentences[i] = nltk.pos_tag(sentence)
# 6. parse the text - forget about it, you'll have to set up a context free grammarWhile in Spacy, it's as short as this, while being way more complete and faster (the pipeline has already been pre-built):
import spacy
nlp = spacy.load('en_core_web_sm')
text = "Hey! I'm going home."
doc = nlp(text)While early LLMs were funny to play with (try playing with GPT-2), they were not very effective. However, the development of LLMs in recent years has opened many doors:
- GitHub Copilot can help someone write code many times faster.
- ChatGPT can answer questions and follow simple instructions similarly to a human.
They are rather good at dealing with language and can be used to overcome many NLP problems such as:
- Simplifying text & convoluted sentences.
- Answering basic questions about the meaning of a sentence.
- Solving coreferences in a text.
- Finding entities in the text.
This will be a tremendous help when trying to process text in the future. However, one must remember that they are, at their core, only predicting a sequence of tokens. Therefore, they have strong limitations (for reasoning for example) to overcome and should be seen as another tool to integrate in the NLP pipeline.
Senses of Words
WordNet is a dictionary which stores the senses of words and the relationships between them.
In a regular dictionary, entries are based on orthograph. When you look at a particular entry, you'll see the different possible meanings below it. See the example below (extract from Oxford Languages).
order
noun
1. the arrangement or disposition of people or things in relation to each other according to a particular sequence, pattern, or method
2. an authoritative command or instruction.
verb
1. give an authoritative instruction to do something
2. request (something) to be made, supplied, or servedThis means that in a regular dictionary, you'll find as many entries as there are words. However, this means that some entries will share the same meaning. This is not the case for WordNet where 1 entry = 1 sense. When you look at a particular entry, you'll see the definition and the words corresponding to it, called lemmas.
orderliness.n.02
- definition = a condition of regular or proper arrangement
- lemmas = orderliness, order
command.n.01
- definition = an authoritative direction or instruction to do something
- lemmas = command, bid, bidding, dictation
order.v.01
- definition = give instructions to or direct somebody to do something with authority
- lemmas = order, tell, enjoin, say
order.v.02
- definition = make a request for something
- lemmas = orderThe most interesting thing with WordNet is that the relations between senses have also been stored, and especially the parent & child senses:
- breakfast → meal - a breakfast is a meal, meal is the parent sense (hypernym, or superordinate)
- meal → lunch - a lunch is a meal, lunch is the child sense (hyponym, or subordinate)
You can explore the tree of senses in wordnet here.
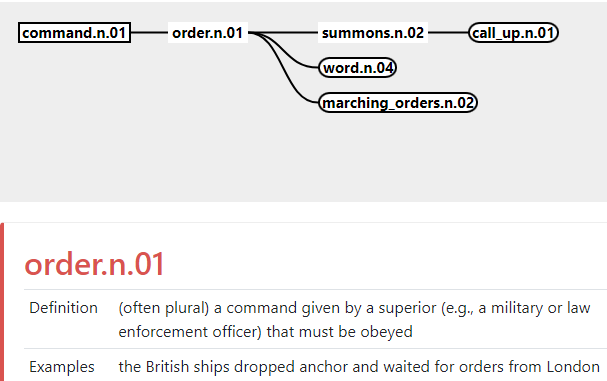
Explore the WordNet database
As you may have noticed, the ID of the sense has 3 components separated by dots, for command.n.01:
- command is one of the lemma of the sense
- n means the word is a noun
- 01 simply distinguishes between different meanings
There are 5 types of words in the WordNet database:
- n = nouns
- v = verbs
- a = head adjectives (or gradable adjective)
- s = satellite adjectives (or non-gradable/absolute adjective)
- r = adverbs
The two different types of adjectives can be explained as such:
- head adjective = bind minimal meaning (e.g. "dry clothes", "perfect day")
- satellite adjective = bind strong meaning (e.g. "dry climate", "perfect timing")
Another interesting thing is that roots have appeared in the graph. For example, all common nouns have the indirect parent entity (proper nouns do not have parents/children senses). This is, however, not the case for the other POS (part of speech), there are 559 root verbs out of a total of 13767 verbs for example.
entity.n.01 = perceived/known/inferred to have its own distinct existence (living or nonliving)
+- abstraction.n.06 = a general concept formed by extracting common features from specific examples
+- physical_entity.n.01 = an entity that has physical existence
+- thing.n.08 = an entity that is not named specificallyUnfortunately, figuring the sense of a word from a sentence is quite difficult. But there are multiple methods to do this.
Firstly, here with the Lesk algorithm, which uses a basic statistical technique by counting the number of similar words in the sentence and previous anotated examples:
word = "bank"
sentence = "I deposited my money in the bank"
sense = nltk.wsd.lesk(sentence, word)
print(sense.definition())
# a container (usually with a slot in the top) for keeping money at home -- this is wrongSecondly, here using the algorithm of Babelfy, which uses "semantic signature" (i.e. a more advanced Lesk algorithm):
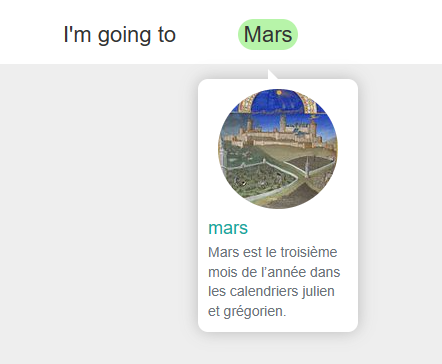
Babelfy wrongly assigns the word sense "Mars" as the month instead of the planet
Thirdly, here is the use of a machine learning algorithm which works using zero-shot or few-shots machine learning tools:
# pip install classy-classification
import spacy
data = {
"bank.n.01": [
"sloping land (especially the slope beside a body of water)",
"they pulled the canoe up on the bank",
"he sat on the bank of the river and watched the currents",
],
"depository_financial_institution.n.01": [
"a financial institution that accepts deposits and channels the money into lending activities",
"he cashed a check at the bank",
"that bank holds the mortgage on my home",
],
"bank.n.03": [
"a long ridge or pile",
"a huge bank of earth",
],
"bank.n.04": [
"an arrangement of similar objects in a row or in tiers",
"he operated a bank of switches",
],
"bank.n.05": [
"a supply or stock held in reserve for future use (especially in emergencies)",
],
"bank.n.06": [
"the funds held by a gambling house or the dealer in some gambling games",
"he tried to break the bank at Monte Carlo",
],
"bank.n.07": [
"a slope in the turn of a road or track; the outside is higher than the inside in order to reduce the effects of centrifugal force",
],
"savings_bank.n.02": [
"a container (usually with a slot in the top) for keeping money at home",
"the coin bank was empty",
],
"bank.n.09": [
"a building in which the business of banking transacted",
"the bank is on the corner of Nassau and Witherspoon",
],
"bank.n.10": [
"a flight maneuver; aircraft tips laterally about its longitudinal axis (especially in turning)",
"the plane went into a steep bank",
],
}
# see github repo for examples on sentence-transformers and Huggingface
nlp = spacy.load('en_core_web_lg')
nlp.add_pipe("classy_classification", config={ "data": data, "model": "spacy" })
print(list(reversed(sorted(nlp("I deposited my money in the bank")._.cats.items(), key=lambda x:x[1]))))
# 1. ('bank.n.01', 0.23873914196413948) -- incorrect
# 2. ('depository_financial_institution.n.01', 0.16675489906573987) -- correct
# 3. ('bank.n.07', 0.08833535400531817) -- incorrectprint('français', wordnet.synset('test.n.05').lemma_names('fra'))
print('italien', wordnet.synset('test.n.05').lemma_names('ita'))
print('espagnol', wordnet.synset('test.n.05').lemma_names('spa'))
print('japonais', wordnet.synset('test.n.05').lemma_names('jpn'))
print('arabe', wordnet.synset('test.n.05').lemma_names('arb'))
print('grec', wordnet.synset('test.n.05').lemma_names('ell'))
print('finois', wordnet.synset('test.n.05').lemma_names('fin'))
# français ['essai', 'test', 'épreuve']
# italien ['cimento', 'esperimento', 'test']
# espagnol ['ensayo', 'prueba']
# japonais ['テスト', 'テスト作業', 'トライアル', 'トライヤル', '試', '試し', '試行', '試験', '験し']
# arabe ['تجْرِبة', 'فحْص']
# grec ['δοκιμή', 'τεστ']
# finois ['koe', 'testi']Information Extraction from Sentence Structure
Here is the list of "universal POS tags" (list from universaldependencies.org), these are the POS tags used by Spacy but not by NLTK.
- ADP = adposition
- definition = preposition or postposition, that indicates the relationship between two words or phrases in a sentence
- examples = in, to, during
- AUX = auxiliary
- definition = helping verb that is used with the main verb in a sentence to convey nuances such as tense, aspect, mood, or voice
- examples = has (done), will (do), he is a teacher
- CCONJ = coordinating conjunction
- definition = connects words, phrases, or clauses of equal grammatical rank within a sentence
- examples = and, or, but
- DET = determiner
- definition = introduces and provides context to a noun
- examples = articles (e.g., "the," "a"), demonstratives (e.g., "this," "those"), possessives (e.g., "my," "his"), and quantifiers (e.g., "some," "many")
- NUM = numeral
- definition = word or symbol that represents a number and is used to denote quantity, order, or a specific position in a sequence
- examples = seventy-four, 3.1415, 5/3, 2023-11-02, 11:24
- PART = particle
- definition = function words that must be associated with another word or phrase to impart meaning and which do not belong to other POS categories
- examples = possessive marker: ‘s, negation particle: not
- PRON = pronoun
- definition = functions as a substitute for a noun or noun phrase, the meaning should be recoverable from the linguistic or extralinguistic context
- examples = everybody, something, they, them, what, who
- SCONJ = subordinating conjunction
- definition = connects a subordinate (dependent) clause to a main (independent) clause
- examples = because, if, while, that
- ADJ = adjective
- definition = modifies or describes a noun or pronoun by providing more information about its qualities, characteristics, or attributes
- examples = happy, big, red
- ADV = adverb
- definition = modifies or describes a verb, adjective, or other adverb, often providing information about how, when, where, or to what degree an action or quality occurs
- examples = quickly, very (but also "end up" or "write down" in english)
- INTJ = interjection
- definition = expresses strong emotion, surprise, or other sudden feelings, often standing alone or followed by an exclamation point
- examples = Yes! Bravo! Hello! Oh, no!
- NOUN = noun
- definition = represents a person, place, thing, idea, or concept
- examples = dog, city, team
- PROPN = proper noun
- definition = specific name used for an individual person, place, organization, or thing and is typically capitalized
- examples = China, John, Mount Everest, Google
- VERB = verb
- definition = expresses action, occurrence, or a state of being
- examples = run, eat, think, is
- PUNCT = punctuation
- definition = symbols in written language to clarify meaning, indicate pauses, and structure sentences
- examples = commas, periods, question marks
- SYM = symbol
- definition = represents an idea, concept, or object
- examples = emojis (🙂, :), ^^, 🤖), currency symbols ($, €), mathematical symbols (<, =, %), etc.
- X = other
- definition = foreign words, gibberish
- examples = I went the the qsfjvnf
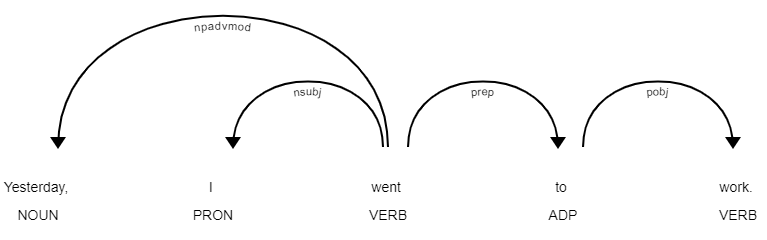
Dependency tree and part of speech tags
Above, there is a dependency tree made using spacy. It clearly shows the relationships between words. List of possible dependencies (from clearnlp-guidelines):
- NSUBJ = nominal subject
- definition = when the subject is a noun or a pronoun (performs an action or is described)
- example = the dog is eating
- NSUBJPASS = nominal subject (passive)
- definition = when the subject is a noun or a pronoun but receiving the action
- example = the book was read
- CSUBJ = clausal subject
- definition = the subject is a clause, which is a group of words containing a subject and a predicate
- example = what he said is true
- CSUBJPASS = clausal subject (passive)
- definition = the subject is a clause receiving the action
- example = whether the project will be approved will be determined by the manager
- AGENT = agent
- definition = this is the noun/pronoun performing the action in a passive phrase
- example = the meal was cooked by the chef
- EXPL = expletive
- definition = word or phrase that serves a grammatical function but carries little or no meaning on its own (usually "it", "that")
- example = it's raining
- DOBJ = direct object
- definition = noun, pronoun, or phrase that directly receives the action of the verb in a sentence, it answers the question "what" or "whom" after the verb
- example = she ate an apple
- DATIVE = dative
- definition = indirect object, typically showing the recipient of an action or the entity that benefits from it
- example = she gave him a gift
- ATTR = attribute
- definition = describes a quality or characteristic of the subject (with a "copula" verb such as "to be", "to seem", "to appear")
- example = she is a talented musician
- OPRD = object predicate
- definition = describes or specifies an attribute of the object in the sentence
- example = she found the room messy ( "the room" is the object, and "messy" is the object predicate)
- CCOMP = clausal complement
- definition = clause that functions as a complement within a sentence, typically completing the meaning of a verb or other related elements
- example = she believes [that he will come]
- XCOMP = open clausal complement
- definition = clausal complement that allows for the presence of an overt subject
- example = I consider [him to be a reliable person]. The subordinate clause "to be a reliable person" has an overt subject ("him").
- ACOMP = adjectival complement
- definition = word, phrase, or clause that provides additional information about an adjective in a sentence
- example = she seems happy [with her new job].
- APPOS = appositional modifier
- definition = noun or noun phrase is placed next to another noun or noun phrase to provide additional information or clarification. This construction is often set off by commas or dashes
- example = my friend, the doctor, is visiting today. My sister, the one with the red hair, is coming to visit.
- ACL = clausal modifier
- definition = clause which provides additional information about a word or phrase in a sentence, often functioning to describe, explain, or qualify
- example = the girl, who just moved in, is very friendly
- RELCL = relative clause modifier
- definition = clausal modifier that begins with a relative pronoun (such as "who," "whom," "whose," "which," or "that") and provides additional information about a noun in the sentence
- example = The woman who lives next door is a doctor. In this sentence, the relative clause "who lives next door" modifies the noun "woman."
- DET = determiner
- definition = introduces a noun and provides more information about it
- example = I bought a new car
- PREDET = pre-determiner
- definition = comes before the main determiner to provide additional information about quantity, extent, or emphasis, further specifying the noun they precede. Common pre-determiners include words like "all," "both," "half," "twice," "such," and "many"
- example = I ate all the cookies. He is such a talented musician.
- NUMMOD = numeric modifier
- definition = provides information about the quantity or numerical value of a noun in a sentence
- example = I have three siblings. There are many birds.
- AMOD = adjectival modifier
- definition = word or group of words that functions as an adjective to provide more information about a noun or pronoun in a sentence
- example = the red car is parked outside
- POSS = possession modifier
- definition = indicates possession or ownership, providing more information about the relationship between the noun it modifies and the owner
- example = This is my house. The cat is Jane's.
- NMOD = modifier of nominal
- definition = adjectives, adjectival phrases, adjectival clauses, or any other element that describes, specifies, or qualifies the noun
- example = She wore a beautiful dress to the party.
- ADVMOD = adverbial modifier
- definition = word or group of words that serves as an adverbial within a sentence, providing additional information about the action, manner, place, time, or other aspects
- example = He walked in the garden.
- ADVCL = adverbial clause modifier
- definition = an adverbial clause modifier, a type of dependent clause introduced by subordinating conjunctions like "when," "where," "because," and "although," functions as an adverbial within a sentence, offering supplementary details about the action, manner, time, place, condition, or purpose of the main clause
- example = She smiled although she was sad.
NEG (negation modifier)
- examples = She does not like coffee. They are doing nothing. He left, but he did not say goodbye.
NPMOD (noun phrase as adverbial modifier)
- example = She worked hard, for her upcoming exams. They met, at the coffee shop.
- POBJ = objects of a preposition
- definition = follows a preposition and complete its meaning within a sentence
- example = She sat on the chair. (preposition = on, object of the preposition = the chair)
- PCOMP = complement of a preposition
- definition = what follows a preposition and completes its meaning within a sentence
- example = The cat is under the table. (preposition = under, complement of the preposition = the table)
- CONJ = conjunct
- definition = individual items being connected by coordinating conjunctions in a sentence
- example = She likes tea and coffee. He is smart, but he is lazy.
- CC = coordinating conjunction
- definition = conjunctions are used to coordinate, combine, or join elements that are similar or contrastive in nature
- example =He likes coffee, and she prefers tea. He studied hard, yet he failed the exam.
- PRECONJ = pre-correlative conjunction
- definition = Correlative conjunctions are pairs of conjunctions that work together to connect words, phrases, or clauses of equal importance. They often appear in pairs, with one part placed before the first element and the other part placed before the second element.
- example = either... or, neither... or, both.. and, not only... but also
- PREP = prepositional modifier
- definition = begins with a preposition and provides additional information in a sentence
- example = The cat on the roof is stuck.
- AUX = auxiliary
- definition = assist the main verb in forming different verb phrases and expressing nuanced meanings
- example = He can speak Spanish.
- AUXPASS = auxiliary (passive)
- definition = refers to the auxiliary verb used to form the passive voice
- example =The cake was baked (past simple passive).
- COMPOUND = compound
- definition = formed by combining two or more words to create a new word with a distinct meaning
- example = post office, science fiction
- PRT = particle
- definition = particles (often prepositions or adverbs) that together with the verb create a new, idiomatic meaning
- example = looked into, gave in, brought up
- CASE = case marker
- definition = linguistic element, often an affix (a morpheme attached to a word), that indicates the grammatical case of a noun or pronoun in a sentence
- example = John's book is on the shelf.
- MARK = marker
- definition = subordinating conjunction (e.g., although, because, while) that introduces an adverbial clause modifier, or a subordinating conjunction (if, that, or whether), that introduces a clausal complement
- example = Although it was raining, they went for a walk. I wonder whether he will come.
- DEP = unclassified dependent
- definition = does not satisfy conditions for any other dependency
- META = meta modifier
- definition = embedded information (comments, pictures, etc.)
- PARATAXIS = parenthetical modifier
- definition = embedded chunk, often surrounded by notations (e.g,. brackets, quotes, commas, etc.)
- PUNCT = punctuation
- ROOT = root
- definition = does not depend on any node in the tree (usually the main verb)
Knowledge Graph
Knowledge graphs are composed of 2 elements:
- nodes - they sometimes have restrictive types (
conceptornamed entityfor example) but they most often do not - edges - they are almost always type restricted between thousands of different possibilities (e.g.
PartOforUsedFor)
Examples of knowledge graphs include:
- DBpedia: knowledge graph made up from structured information from Wikipedia.
- Wikidata: free and open knowledge base which acts as a database for structured data of Wikimedia projects, including Wikipedia.
Domain Knowledge Graph
I've been influenced by the talk on domain driven design (DDD) of Scott Wlaschin: https://fsharpforfunandprofit.com/ddd. The talk is about a programming paradigm where you try to design your model based on how the real world is working. This means there shouldn't be a language barrier when a developper talks about how the program works with a non-developper who has deep knowledge of the company's business.
The idea here is to create an object oriented model to be able to ask more complex questions easily without repeating oneself. For example, once the model learns about a new person, it knows it can ask questions such as "What is <person>'s job?", then ask whether this is a good place to work, etc.
class Person:
name: str = None
gender: str = None
age: int = None
personality: str = None
location: str = None
job: Job = None
family: Family = None
friends: list['Friend'] = []
class Family:
father: 'Person'
mother: 'Person'
brothers: list['Person']
sisters: list['Person']
daughters: list['Person']
sons: list['Person']
family_structure: FamilyStructure
class Company:
name: str
size: TeamSize
location: str
class Job:
job_name: str
colleagues: list['Person']
company: Company
class Hobby:
name: str
location: str
frequency: str
cohobbyists: list[Person]general_questions: list[str] = [
"Let's change focus a bit... Tell me about yourself.",
"Let's change focus a bit... Tell me about your family.",
"Let's change focus a bit... Tell me about your childhood.",
"Let's change focus a bit... Tell me about your parents.",
"Let's change focus a bit... Tell me about your partner.",
"Let's change focus a bit... Tell me about your job.",
"Let's change focus a bit... Tell me about your friends.",
]
user_conditional_questions: list[tuple[Callable, str]] = [
( (lambda user: user.age is None), 'How old are you?' ),
( (lambda user: user.name is None), 'What\'s your name?' ),
( (lambda user: user.gender is None), 'How do you identify in terms of gender? (e.g., male, female)?' ),
( (lambda user: user.location is None), 'Where do you live?' ),
( (lambda user: user.job is None), 'What\'s your job?' ),
]